The February release of Microsoft Power BI Desktop unveiled the public preview of a transformative DAX feature – visual calculations. This new feature promises to revolutionize the way calculations are written, making them more intuitive and user-friendly than ever before. As we unpack the layers of this innovation, we’ll discover how it simplifies the creation of dynamic and complex reports, empowers users of all skill levels, and addresses some of the most persistent challenges in data modeling. Given the breadth and depth of this subject, a series of articles is required to sufficiently cover it. In this first article, we begin by exploring one of the motivations for the introduction of visual calculations.
Before the introduction of visual calculations, Power BI users primarily relied on measures to perform calculations within their reports. Measures are a fundamental and distinctive feature offered by Power BI, and they are the primary reason DAX was invented. The power of measures lies in their reusability – you can write a formula once and save it in the semantic model. Then, report creators can simply drag and drop it onto any visual in any report, and it will just work, even in reports you never anticipated initially. This capability is not available with SQL or Python, at least not yet. Although there is a proposal to introduce measures to SQL, it remains just a proposal for now. For the magic of reusability to work, every measure must be independent. For example, [measure 2] = IF([measure 1] > 1000, [measure 1]) means that [measure 2] can calculate [measure 1] internally by itself, without requiring [measure 1] to be added to the same report first. This is convenient and impressive, but what if users also include [measure 1] on the same report? In that case, will [measure 2] be able to take advantage of the values of [measure 1] that are already calculated? Unfortunately, the answer is “it depends,” and it is complicated.
The independent nature of DAX measures can initially surprise users accustomed to other reporting tools, contributing to a significant learning curve for DAX beginners. For example, consider a simple report that includes both the sum of sales and the sum of quantity. A SQL user might typically expect the underlying query to resemble:
SELECT SUM("SalesAmount"), SUM("OrderQuantity") FROM "FactInternetSales"However, in the DAX world, assuming there are two DAX measures in a DirectQuery model:
[Total Sales] = SUM('FactInternetSales'[SalesAmount])
[Total Quantity] = SUM('FactInternetSales'[OrderQuantity])This setup would lead to two separate SQL queries if the DAX Engine were to evaluate each measure independently:
SELECT SUM("SalesAmount") FROM "FactInternetSales"
SELECT SUM("OrderQuantity") FROM "FactInternetSales"It may be surprising to DAX newcomers that even straightforward measures like these could be costly to evaluate if the DAX Engine had adopted a naive execution plan. To reduce redundant calculations, the DAX Engine uses a technology known as fusion, which combines leaf-level calculations into fewer queries to the underlying storage engine, thus optimizing performance. For a visual representation of how fusion optimizes calculations in the DAX Engine, refer to Figure 1. Returning to our earlier example, even if a user includes both [measure 1] and [measure 2] in the same visual, the DAX Engine does not reuse the results of [measure 1] when calculating [measure 2]. Instead, [measure 2] calculates [measure 1] independently. During this process, the leaf-level nodes of [measure 2] might either access the Vertipaq engine cache if [measure 1] has already been calculated, or they may benefit from the fusion optimization to consolidate with the leaf-level nodes of [measure 1].

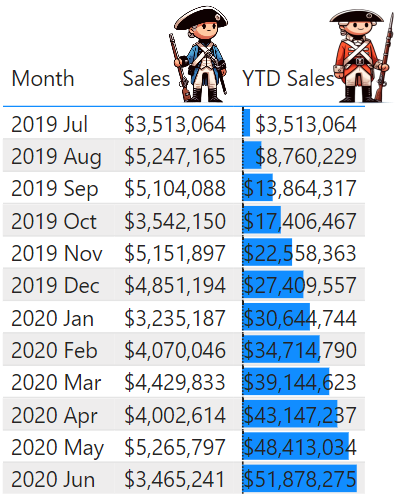
In this article, we will not explore further into the territory of fusion. The mention here serves merely to illustrate the extensive engineering efforts that have been poured into the DAX query optimizer to avoid the prohibitively expensive naive execution plans. The remarkable reusability of DAX measures stems from their design principle of logical independence, which, while seemingly straightforward, requires complex execution plans to merge separate calculations into consolidated operations. Let’s examine a case where this independence leads to suboptimal execution. Refer to Figure 2, which shows a table visual with [Sales] measure values for each month in a fiscal year next to the [YTD Sales] measure, representing the cumulative sums from the beginning to the end of that period. It might seem logical that the [YTD Sales] values could be derived by summing the monthly [Sales] data. However, closer scrutiny reveals that each measure is computed separately. To demonstrate this, four VertiPaq SE Query End events were captured and presented beneath Figure 2, each corresponding to a storage engine query invoked by the DAX query for this visual. Without explaining the specific functions of each storage engine query, it is obvious that the [YTD Sales] measure was calculated independently, resulting in its own set of queries to the Vertipaq Engine.
⚠ For a hands-on experience with the examples used to create Figures 2 and 4, you can download the corresponding pbix from the following link: Download pbix file.
-- Q1
SELECT [Date].[Month], [Date].[MonthKey]
FROM [Date]
WHERE [Date].[Fiscal Year] = 'FY2020';
-- Q2
SELECT [Date].[Date Value], [Date].[Month], [Date].[MonthKey]
FROM [Date]
WHERE [Date].[Fiscal Year] = 'FY2020';
-- Q3
SELECT [Date].[Date Value], SUM([Internet Sales].[SalesAmount])
FROM [Internet Sales] LEFT OUTER JOIN [Date] ON [Internet Sales].[OrderDateKey]=[Date].[DateKey]
WHERE [Date].[Date Value] IN (43666.000000, 43707.000000, 43748.000000, 43789.000000, 43830.000000, 43871.000000, 43680.000000, 43721.000000, 43762.000000, 43803.000000...[366 total values, not all displayed]);
-- Q4
SELECT [Date].[Month], [Date].[MonthKey], SUM([Internet Sales].[SalesAmount])
FROM [Internet Sales] LEFT OUTER JOIN [Date] ON [Internet Sales].[OrderDateKey]=[Date].[DateKey]
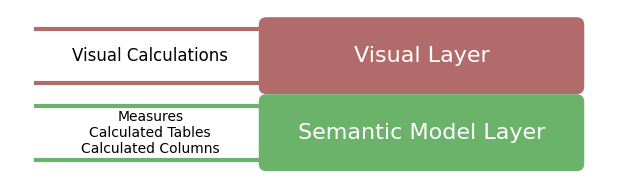
WHERE [Date].[Fiscal Year] = 'FY2020';Although the DAX Engine development team will continue to create new algorithms to enhance calculation performance, it is impractical to expect them to cover the vast and rapidly growing diversity of DAX expressions in use globally. Similarly, it is unrealistic to expect that every user will achieve expert-level proficiency in row contexts and filter contexts, and thus be able to craft perfectly optimized formulas in all situations. To address this challenge, visual calculations were conceived as a new method for defining calculations directly on top of filtered and aggregated data, thereby completely avoiding the possibility of accidental, expensive scans on physical tables. These visual calculations exist exclusively within the visual layer, separate from the measures located in the semantic model layer, as depicted in Figure 3. This segregation ensures that DAX calculations at each layer have access only to objects within their own layer, allowing authors to immediately determine whether their calculations are interacting with raw data in physical tables or operating solely on filtered and aggregated data. This delineation simplifies the design process, rendering it more intuitive and less prone to errors for users of all skill levels.
Returning to the earlier example of the two measures as shown in Figure 2, I replaced the [YTD Sales] measure with an equivalent visual calculation and achieved the same results, which are displayed in Figure 4. This change resulted in only a single VertiPaq SE Query End event, copied below the figure. ⚠ As visual calculations are still in public preview, some functionalities like number formatting and conditional formatting on the fields are not yet available. These limitations will be lifted before the feature is released for general availability.

SELECT [Date].[Month], [Date].[MonthKey], SUM([Internet Sales].[SalesAmount])
FROM [Internet Sales] LEFT OUTER JOIN [Date] ON [Internet Sales].[OrderDateKey]=[Date].[DateKey]
WHERE [Date].[Fiscal Year] = 'FY2020';In this article, we have taken a first look of a new layer of calculation and examined one of the motivations for its development. We have discovered that the reusability of DAX measures originates from their logical independence, which necessitates complex execution strategies to reduce redundant and inefficient calculations. Consequently, this can pose a significant challenge for DAX measure authors to craft efficient calculations that satisfy complex business requirements and to debug performance issues when bottlenecks occur. Visual calculations, by operating within the visual layer, naturally circumvent such problems by relying exclusively on filtered and aggregated measure query results. Therefore, visual calculations provide DAX developers with a simple mental model for writing efficient calculations.
With visual calculations, DAX has finally broken through the confinement of the semantic model layer, gaining first-class access to report-level artifacts. This advancement unlocks a multitude of opportunities that extend far beyond enhancing performance. Exploring the various aspects of this new calculation type will require several follow-up blog posts. As the feature is currently in the public preview phase, the product team has greater flexibility to implement significant improvements. We welcome feedback through all channels to help us refine the feature quickly before it reaches general availability.













































 Although the following syntax is also accepted by the DAX engine today, it is not by design so you should only use curly braces {} instead of parentheses () to enclose a list of values or tuples, the latter of which should be enclosed in ().
Although the following syntax is also accepted by the DAX engine today, it is not by design so you should only use curly braces {} instead of parentheses () to enclose a list of values or tuples, the latter of which should be enclosed in ().